
![[Pytorch] Pnemonia Prediction Model – GradCam post thumbnail image](https://badagreen.store/wp-content/uploads/2024/01/image-19.png)
CAM (Class Activation Map)
보통 CNN의 구조를 생각해보면, Input – Conv Layers – FC Layers 으로 이루어졌습니다. CNN의 마지막 레이어를 FC-Layer 로 Flatten 시키면 각 픽셀들의 위치 정보를 잃게 됩니다. 따라서 Classification의 정확도가 아무리 높더라도, 우리는 그 CNN 이 무엇을 보고 특정 class로 분류했는지 알 수 없었습니다.
2016년 공개된 논문 Learning Deep Features for Discriminative Localization에서는 FC Layer 대신에, GAP (Global Average Pooling) 을 적용하면 특정 클라스 이미지의 Heat Map 을 생성할 수 있고, 이 Heat Map 을 통해 CNN 이 어떻게 그 이미지를 특정 클라스로 예측했는지를 이해할 수 있다고 주장하고 있습니다.
GradCAM 구하는 방법
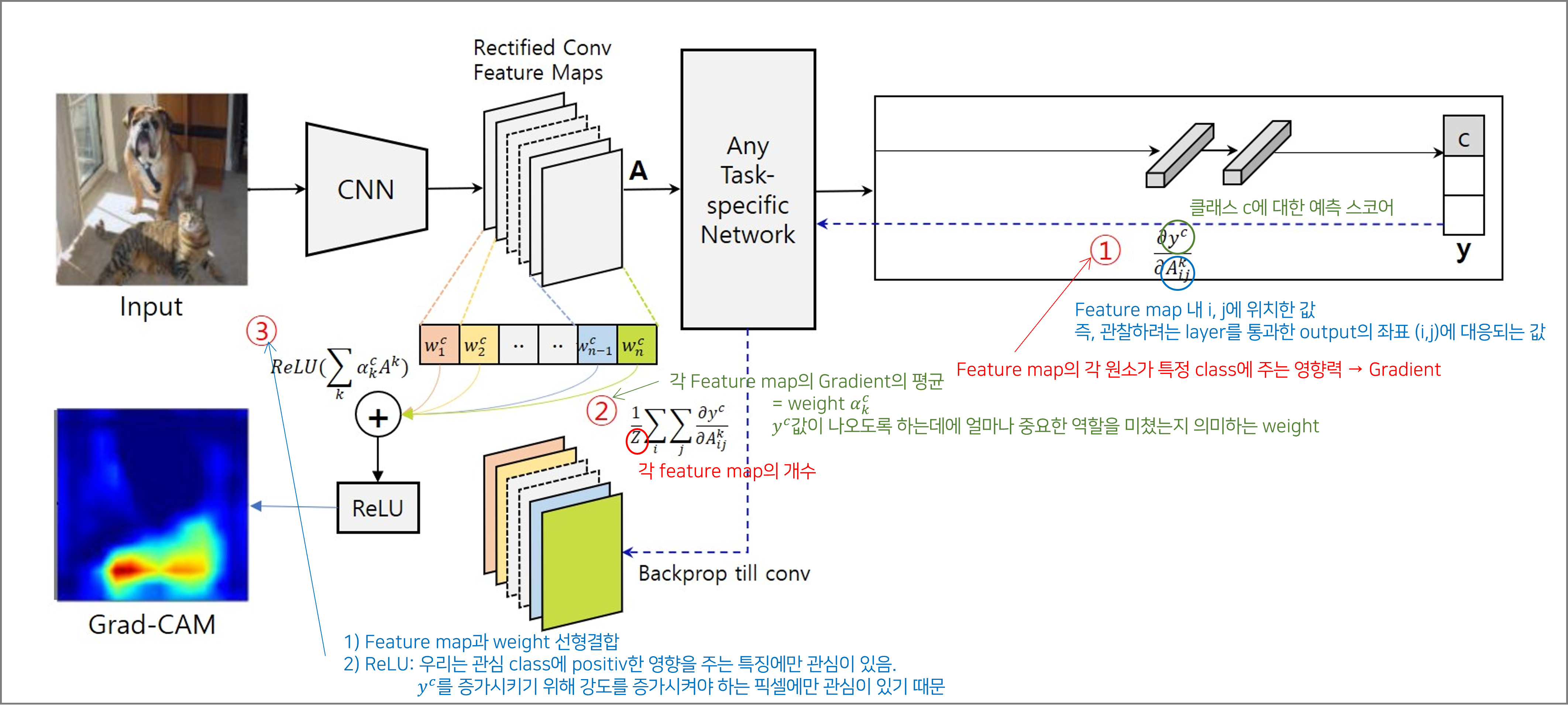

다음과 같이 Pneumonia 데이터셋은 아래와 같이 결과를 구현
# 필수 라이브러리들
import time
import copy
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, models, transforms
from PIL import Image
import torch.nn.functional as F
import cv2
# VGG16 모델을 초기화합니다. 이 때 pretrained=False로 설정하여 미리 학습된 가중치를 로드하지 않습니다.
# 우리는 이 모델을 폐렴 감지 작업에 맞게 수정할 것이기 때문입니다.
model = models.vgg16(pretrained=False)
# 폐렴 분류를 위해 모델의 마지막 분류 레이어를 변경합니다.
# 원래 VGG16 모델은 1000개의 클래스에 대한 예측을 위해 설계되었지만,
# 폐렴 감지 작업에는 '정상'과 '폐렴'의 두 가지 클래스만 필요합니다.
# 따라서, 이 레이어를 두 클래스의 예측을 위한 새로운 레이어로 변경합니다.
num_features = model.classifier[6].in_features
model.classifier[6] = nn.Linear(num_features, 2) # 클래스가 2개라고 가정
# GPU 사용 설정
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 이제 변경된 구조에 맞게 학습된 가중치를 로드할 수 있습니다.
# 이 가중치는 두 클래스를 구분하기 위해 학습된 것이므로, 모델의 수정된 구조와 호환됩니다.
model.load_state_dict(torch.load('./pneumonia_weight.pt'))
# 모델을 평가 모드로 설정합니다.
model.eval()
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=2, bias=True)
)
)
def process_image(image_path):
image = Image.open(image_path).convert('RGB') # 이미지를 RGB로 변환
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image_tensor = preprocess(image).unsqueeze(0) # 배치 차원 추가
return image_tensor
# Grad-CAM 적용 함수
def apply_grad_cam(model, img_tensor, target_layer):
# 모델의 예측 결과에 대한 그래디언트를 얻기 위해 hook을 사용합니다.
gradients = None
def backward_hook(module, grad_in, grad_out):
nonlocal gradients
gradients = grad_out[0]
# 모델의 마지막 컨볼루션 레이어의 출력을 얻기 위해 hook을 사용합니다.
activations = None
def forward_hook(module, input, output):
nonlocal activations
activations = output
# hook 등록
forward_handle = target_layer.register_forward_hook(forward_hook)
backward_handle = target_layer.register_backward_hook(backward_hook)
# 정방향 패스 실행
output = model(img_tensor)
# 활성화된 클래스 인덱스를 얻습니다 (예측된 클래스)
_, pred_idx = torch.max(output.data, 1)
# 역전파 실행
model.zero_grad()
class_loss = F.cross_entropy(output, pred_idx)
class_loss.backward()
# hook 제거
forward_handle.remove()
backward_handle.remove()
# 그래디언트 가중 평균 계산
pooled_gradients = torch.mean(gradients, dim=[0, 2, 3])
# 가중 평균을 활성화 맵에 곱합니다.
for i in range(pooled_gradients.size(0)):
activations[:, i, :, :] *= pooled_gradients[i]
# 활성화 맵을 평균냅니다.
heatmap = torch.mean(activations, dim=1).squeeze()
# ReLU 적용 (음수 값을 제거합니다)
heatmap = np.maximum(heatmap.cpu().detach().numpy(), 0)
# 히트맵을 원본 이미지의 크기로 조정합니다.
heatmap = cv2.resize(heatmap, (img_tensor.shape[2], img_tensor.shape[3]))
heatmap = (heatmap - heatmap.min()) / (heatmap.max() - heatmap.min())
# 히트맵을 색상으로 변환합니다.
heatmap = np.uint8(255 * heatmap)
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
# 원본 이미지와 히트맵을 합성합니다.
img_original = img_tensor.cpu().detach().numpy()[0].transpose(1, 2, 0)
img_original = ((img_original - img_original.min()) * (1/(img_original.max() - img_original.min()) * 255)).astype('uint8')
overlayed_img = cv2.addWeighted(img_original, 0.6, heatmap, 0.4, 0)
# 시각화를 위해 matplotlib를 사용합니다.
plt.imshow(overlayed_img)
plt.axis('off')
plt.show()
def plot_image(image_tensor):
# Remove the batch dimension
image_tensor = image_tensor.squeeze(0)
# Undo the normalization
inv_normalize = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.225]
)
image_tensor = inv_normalize(image_tensor)
# Clamp the image data to valid range [0, 1] for displaying
image_tensor = torch.clamp(image_tensor, 0, 1)
# Convert to PIL image and then display using matplotlib
image = transforms.ToPILImage()(image_tensor)
plt.imshow(image)
plt.axis('off') # Hide the axes
plt.show()
# 이미지 경로 설정
image_path = '/home/badagreen/다운로드/archive/chest_xray/test/PNEUMONIA/person91_bacteria_449.jpeg' # 실제 이미지 경로로 변경하세요.
# 이미지 전처리
img_tensor = process_image(image_path)
plot_image(img_tensor)
# 모델을 통한 예측 수행
model.eval() # 모델을 평가 모드로 설정
model.to(device) # Ensure model is on the same device as input tensor
# 모델을 통한 예측 수행
with torch.no_grad():
# Ensure input tensor is on the same device as model
img_tensor = img_tensor.to(device)
outputs = model(img_tensor)
_, preds = torch.max(outputs, 1)
predicted_class = preds.item()
print('predicted_class :',predicted_class)
# 클래스 레이블 설정 (이 예에서는 0이 '정상', 1이 '폐렴'으로 가정)
classes = ['정상', '폐렴']
print(f"모델 예측: {classes[predicted_class]}")
target_layer = model.features[-1] # VGG의 예시입니다.
img_tensor = process_image(image_path).to(device)
apply_grad_cam(model, img_tensor, target_layer)
predicted_class : 1
모델 예측: 폐렴
