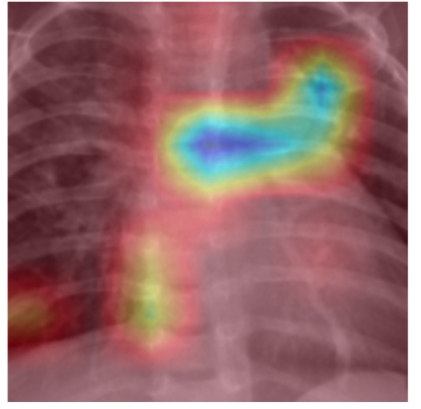
Pytorch를 이용하여 사내에서 학습을 해야하는 환경이 있어 GPU환경이 잘 설정되었는지 테스트겸 Kaggle에서 데이터셋을 다운로드 받고 학습을 돌렸다. 오랜만에 AI 쪽 업무를 하려니 많이 까먹기도 재밌어지기도 했다.
데이터셋 리뷰
https://www.kaggle.com/datasets/paultimothymooney/chest-xray-pneumonia
Kaggle의 폐렴 X-레이 데이터셋은 폐렴 환자의 X-레이 이미지와 정상 이미지를 모아 놓은 것입니다. 데이터셋은 Train / Test /Val에서 Normal과 Pneumoia Tree 구조로 되어있다.
학습데이터는 많지는 않아서 학습에는 오래걸리지 않을것으로 예상된다.
학습모델( VGG16 )
VGG16은 옥스퍼드 대학 연구팀에 의해 개발된 컨볼루션 신경망(Convolutional Neural Network, CNN) 아키텍처입니다. 이 모델은 ImageNet 대회(ILSVRC)에서 좋은 성능을 보여주었으며, 그 구조 때문에 이미지 인식과 분류에서 널리 사용되고 있습니다.
VGG16을 사용하는 이유는 다음과 같습니다:
- 단순하고 깊은 구조: VGG16은 모든 컨볼루션 레이어에서 3×3 필터를 사용하고, 깊이에 따라 특징을 추출합니다. 이는 모델이 복잡한 특징까지 학습할 수 있게 해 줍니다.
- 전이 학습(Transfer Learning)에 적합: VGG16은 다양한 이미지 데이터셋에서 사전 학습이 가능하며, 작은 데이터셋에 대해서도 좋은 성능을 보입니다. 폐렴 데이터셋 같은 특정 의료 영상에 적용할 때도 유용합니다.
- 강력한 기능 추출: VGG16의 다층 구조는 다양한 수준에서의 특징을 추출할 수 있게 하여, 복잡한 이미지 내의 중요한 패턴을 인식할 수 있습니다.
VGG16의 레이어 구조는 크게 다음과 같습니다:
- 입력 레이어: 224x224x3 크기의 이미지를 입력받습니다.
- 컨볼루션 레이어(Convolutional Layers): 총 13개의 컨볼루션 레이어가 있으며, 모두 3×3 크기의 필터를 사용합니다. 첫 번째 두 레이어는 64개의 채널을 가지고 있으며, 레이어가 깊어질수록 채널의 수가 두 배씩 증가합니다 (128, 256, 512).
- 풀링 레이어(Pooling Layers): 각 컨볼루션 블록 뒤에 2×2 맥스 풀링 레이어가 위치하여 공간적 차원을 줄입니다.
- 완전 연결 레이어(Fully Connected Layers): 마지막 컨볼루션 레이어 다음에는 세 개의 완전 연결 레이어가 있으며, 첫 번째 두 레이어는 각각 4096개의 뉴런을 가지고, 마지막 레이어는 분류를 위한 1000개의 뉴런(이 경우 폐렴 분류를 위해 클래스 수에 맞게 조정될 수 있음)을 가집니다.
- 출력 레이어: 소프트맥스 활성화 함수를 사용하여 클래스 확률을 출력합니다.
VGG16의 깊이와 방대한 수의 학습 파라미터는 강력한 분류 능력을 가능하게 하지만, 동시에 많은 계산 리소스를 요구하며, 오버피팅의 위험도 있습니다. 이를 방지하기 위해 데이터 증강(Data Augmentation), 드롭아웃(Dropout), 가중치 규제(Weight Regularization) 등의 기술을 함께 사용할 수 있습니다.
폐렴 데이터셋과 같은 의료 영상을 처리할 때, VGG16은 이미지의 미묘한 패턴을 학습할 수 있는 충분한 깊이를 제공하므로 선택해서 사용했다. 솔직히 모델이중요한가…데이터가 중요하지

# 필수 라이브러리들
import time
import copy
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, models, transforms
# GPU 사용 가능 여부 확인
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("사용할 장치:", device)
!nvidia-smi

# 환경을 설치했으니 확인해보자
print(torch.cuda.is_available())
print(torch.version.cuda)
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
# 데이터 경로 설정
data_dir = '/home/badagreen/다운로드/archive/chest_xray/chest_xray' # 데이터셋 디렉토리 경로
train_dir = data_dir + '/train'
test_dir = data_dir + '/test'
# 이미지 전처리
transform = transforms.Compose([
transforms.Resize((256, 256)), # 이미지 크기 조정
transforms.ToTensor(), # 이미지를 PyTorch Tensor로 변환
])
# 데이터셋 로드
train_dataset = datasets.ImageFolder(root=train_dir, transform=transform)
val_dataset = datasets.ImageFolder(root=test_dir, transform=transform)
# 데이터로더 설정
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True, pin_memory=True) # 배치 크기를 16에서 8로 줄임
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=False, pin_memory=True)
dataloaders = {'train': train_loader, 'val': val_loader}
# VGG-16 모델 불러오기 및 분류기 수정
model = models.vgg16(pretrained=True)
num_features = model.classifier[6].in_features
model.classifier[6] = nn.Linear(num_features, 2) # 클래스가 2개라고 가정
# GPU 사용 설정
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 손실 함수 및 최적화 알고리즘 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
def train_epoch(model, dataloader, criterion, optimizer, device):
model.train() # 모델을 학습 모드로 설정
running_loss = 0.0
correct = 0
total = 0
for images, labels in dataloader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad() # 그래디언트 초기화
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward() # 역전파
optimizer.step() # 가중치 갱신
running_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
epoch_loss = running_loss / len(dataloader.dataset)
epoch_acc = 100 * correct / total
return epoch_loss, epoch_acc
def validate_epoch(model, dataloader, criterion, device):
model.eval() # 모델을 평가 모드로 설정
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in dataloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
epoch_loss = running_loss / len(dataloader.dataset)
epoch_acc = 100 * correct / total
return epoch_loss, epoch_acc
import torch
# GPU를 사용해야한다!!
# GPU 사용 가능 -> True, GPU 사용 불가 -> False
print(torch.cuda.is_available())
# GPU 사용 가능 -> 가장 빠른 번호 GPU, GPU 사용 불가 -> CPU 자동 지정 예시
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
# 사용 가능 GPU 개수 체크
print(torch.cuda.device_count()) # 3
print(device) # 3
# 학습 파라미터 설정
num_epochs = 5
learning_rate = 0.001
# 모델, 손실 함수, 최적화 알고리즘 정의ㅖㅒ쟤ㅐ
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
# 학습 및 검증 루프
for epoch in range(num_epochs):
train_loss, train_acc = train_epoch(model, train_loader, criterion, optimizer, device)
val_loss, val_acc = validate_epoch(model, val_loader, criterion, device)
print(f'Epoch {epoch+1}/{num_epochs}')
print(f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%')
print(f'Validation Loss: {val_loss:.4f}, Validation Acc: {val_acc:.2f}%\n')
#torch.save(model.state_dict(), './pneumonia_weight.pt')